Hiroki Arimura, Atsushi
Wataki, Ryoichi Fujino, and Setsuo Arikawa
A
Fast Algorithm for Discovering Optimal String Patterns in Large Text Databases
Быстрый алгоритм для обнаружения оптимальных образцов в больших базах данных
Перевод: Погорский Н.В.
2004
Содержание
2.2 Задача
получения данных (data mining problem)
3.1 Перечисление
образцов в канонической форме с использованием суффиксного дерева
3.2 Вычисление
значений поддержки с использованием региональных запросов
5 Agnostic
PAC-learning и
минимизация эмпирической ошибки
7 Экспериментальные результаты.
Резюме
Мы рассмотрим проблему выборки данных (data mining problem) в больших наборах неструктурированных текстов, основанную на правилах зависимости между подсловами текста. Образец зависимых слов есть выражение такое как
(TATA,30,AGGAGGT) à C
- выражает правило, по которому если текст содержит подстроку TATA, и следующую за ней подстроку AGGAGGT с расстоянием между ними не более 30 символов, то свойство C с высокой вероятностью будет выполняться. Решение проблемы оптимизации доверия образца представляет собой часто встречающиеся образцы (a, k, b), которые оптимизируют доверие по отношению к данному набору текстов. Хотя существует прямой алгоритм, решающий эту задачу за полиномиальное время, который перечисляет все возможные образцы за время O(n5), мы сосредоточимся на рассмотрении более эффективных алгоритмов, которые могут быть применены к большим базам данных. Мы представим алгоритм, который решает задачу оптимизации доверия образца за время O(max{k,m}n2) с использованием памяти O(kn), где m и n – количество и общая длина классифицируемых исходных данных соответственно, k – небольшая константа в диапазоне около 30-50. Этот алгоритм сочетает в себе структуру данных суффиксные деревья и алгоритм регионального поиска (региональные запросы, orthogonal range query), которые ускоряют вычисления. Кроме того, для большинства случайных текстов, таких как последовательности ДНК, мы увидим, что модифицированный алгоритм работает за время O(kn*log(n)3), используя память O(kn). Мы также обсудим некоторые эвристики, такие как осуществление выборки (sampling) и обрезание (pruning) как практические усовершенствования. Затем мы оценим эффективность и работу алгоритмов для эксперимента с генетическими последовательностями. Также обсуждается связь с эффективным Agnostic PAC-learning.
1 Введение
Недавний прогресс связи и сетевых технологий, таких как электронная почта, всемирная паутина, и др. сделали простым накопление больших массивов неструктурированных и полуструктурированных текстовых данных [1]. Такие текстовые базы данных могут быть наборами web-страниц или SGML документов (OPENTEXT Index [26]), баз данных белков (GenBank [11]), online – словарей (OED [13]) и другими очевидными текстовыми данными в файлах. Имеется потенциальный спрос на эффективные методы поиска полезной информации в текстовых базах данных, отличные от существующих методов доступа к информации [1, 19, 28].
Получение данных (data mining) – область исследования, цель которой – разработка полуавтоматических инструментов для поиска полезной информации в больших базах данных. Эта область появилась в начале 90-х годов прошлого века и обширно разработана и в теории и в практике [2, 10, 15]. Однако существующие технологии получения данных имеют дело с хорошо структурированным данными, такими как реляционными базами с булевыми или числовыми атрибутами [2, 10, 15], и, таким образом, напрямую не применимы к неструктурированным массивам данных. Это происходит потому, что текстовые базы данных представляют собой просто набор неструктурированных строк и количество данных огромно, в пределах от мега до терабайт. Мы сосредоточимся на эффективных и адекватных методах поиска, которые работают для больших наборов неструктурированных данных [9, 19, 23, 28].
В этой работе мы рассмотрим поиск очень простого образца, называемого образец зависимых k-близких слов. Возьмем набор текстов S и целевое условие С на S. Образец зависимых k-близких слов – это выражение вида
(TATA, 30, AGGAGGT) à C,
которое выражает правило, по которому если текст содержит подстроку TATA, и следующую за ней подстроку AGGAGGT с расстоянием между ними не более 30 символов, то свойство C для этого текста с высокой вероятностью будет выполняться. Хотя этот класс правил кажется очень ограниченным, они более гибкие для описания локального подобия в текстах с контекстной информацией, чем неупорядоченные наборы ключевых слов или единичных подслов. Следовательно, этот тип правил часто используется в приложениях биоинформатики [12], библиографического поиска [13], и поиска в интернете [26]. Далее, как мы увидим в этой работе, простота класса позволяет адекватно и эффективно работать с зашумленными средами.
Как структуру получения данных мы принимаем так называемый оптимальный образец поиска, недавно предложенный Фукудой (Fukuda) и др. [10]. В их структуре алгоритм поиска получает типовой набор S с целевым свойством C: S –> {0,1} и ищет все/некоторые образцы P, которые максимизируют некоторый критерий. На основании этой структуры мы рассмотрим эффективную разрешимость задачи оптимизации доверия образца и задачи минимизации эмпирической ошибки (Kearns, Shapire, Sellie [17]; Maass [20]).
Задача оптимизации доверия образца может быть решена прямым алгоритмом за время O(n5), который перебирает O(n4) возможных образцов зависимых слов, т.к. самое большое имеется O(n2) возможных подслов. Однако этот полином слишком велик, чтобы применять алгоритм в реальных приложениях. В разделе 3 и 4 мы представим модификации алгоритма, которые находят все образцы зависимых слов, используя структуру данных для обработки тек стов – суффиксные деревья и алгоритм вычислительной геометрии – региональный поиск. Идея состоит в сведении поиска такого образца к рассмотрению прямоугольника со сторонами, параллельными осям, на двумерной плоскости рангов суффиксов.
В 3-ем разделе мы представим алгоритм, выполняющийся за время O(mn2 log2(n)), использующий память O(kmn log(n)), где m и n – количество и общая длина текстов соответственно, k – близость слов. Далее, в 4-ом разделе, осуществляя региональный поиск прямо на суффиксном дереве, мы получим модифицированную версию алгоритма, оценка времени которого O(max{k,m}n2) и памяти O(kn) в самом плохом случае. Для большинства почти случайных текстов, таких как последовательности ДНК, известно, что глубина суффиксного дерева ограничена O(log n). Тогда мы видим, что наш алгоритм может быть преобразован так, что время работы станет O(kn log(n)3) для таких случайных текстов.
В 5-ом разделе, мы описываем приложение [to computational learning theory]. Мы увидим, что наш алгоритм из 4-го раздела может быть преобразован для эффективного решения задачи минимизации эмпирической ошибки. В заключении мы получим эффективный Agnostic PAC-learner для класса образцов зависимых k-близких слов. Nakanishi и др. [25] изучают проблему последовательности (consistency problem), которая является частным случаем задачи минимизации эмпирической ошибки для класса одиночных подстрок. Т.к. одиночная подстрока является частным случаем образца зависимых k-близких слов, мы обобщаем их результат.
В 6-ом разделе, мы вводим некоторые эвристики и анализируем их. В 7-ом разделе мы оцениваем эффективность и работу нашего алгоритма с эмпирической точки зрения, проводя эксперименты с генетическими последовательностями. В заключение, в 8-ой секции мы обобщаем результаты.
2 Предварительные сведения
2.1 Тексты и образцы
Пусть S – конечный алфавит. Мы всегда принимаем фиксированным порядок букв в алфавите S. Если s – строка, S – множество строк, тогда |s| обозначим длину строки, а size(S) – общую длину строк во множестве S. Если существуют некоторые u, v, w Î S*, такие что t = uvw, тогда говорят что u, v и w – префикс, подслово и суффикс t соответственно. Текстом называется любая строка над алфавитом S. За t[i] обозначим i-ую букву в слове t. Местонахождение строки s в t есть целое положительное число i, такое что t[i]…t[i+|t|-1] = s.
Пусть k – целое неотрицательное число. Образец зависимых k-близких слов (k-proximity two words association pattern), или кратко - образец, есть тройка P = (a,k, b) где a,b Î S* - строки над алфавитом S, k³0 – параметр близости слов. Образец удовлетворяет строке s, если существует пара p,q – целые, такая что p и q есть местонахождения строк a и b соответственно, удовлетворяющая неравенствам 0£q-p£k. Пара (p,q) называется местонахождением образца P в строке t. Обозначим число элементов множества S за card(S). Пусть i, j – целые неотрицательные, тогда [i..j] обозначает интервал {i, i+1, …, j} если i£ j или Æ (пустое множество) в противном случае.
2.2 Задача получения данных (data mining problem)
Выборкой называется конечное множество S = {s1,…,sm} строк над алфавитом S и целевое условие на S – двоичная функция С: S®{0,1}. Каждая строка si Î S называется документом, C(si) – его метка. Документ si положительный(позитивный) если C(si) = 1 и отрицательный (негативный) в противном случае. Пусть a - некоторая метка. Обозначим за Sa множество {sÎS | C(s) = a}. Для подмножеств T множества S, мы определим count(P,T) как число документов s Î T удовлетворяющих образцу P.
Первая рассматриваемая проблема – максимизация доверия (confidence maximization) [10]. Для образца P определим поддержку P как supps(P) = count(P,S1)/card(S) и доверие P как confs(P) = count(P,S1)/count(P,S). Минимальная поддержка – действительное число 0£s£1. Образец P считают s-частым если supps(P) ³ s.
Определение 1. Задача оптимизации доверия образца (Optimized Confidence Pattern Problem). Дана пятерка объектов (S, S, C, k, s) – алфавит S, выборка S, целевое условие C на S, константы k³0 и 0£s£1. Задача состоит в нахождении s-частого образца зависимых k-близких слов P, который максимизирует confs(P).
Другими словами, задача оптимизации доверия образца состоит в нахождении значений образца P®C с наивысшей условной вероятностью среди тех правил, которые удовлетворяют по крайней мере s процентам документов в S. В 3-ем и 4-ом разделе приводятся эффективные алгоритмы для решения этой задачи.
Вторая проблема – рассмотрение минимизации эмпирической ошибки [17,20]. Пусiть S – выборка, С – целевое условие на S, P - образец зависимых k-близких слов над алфавитом S. Определим P(s)Î{0,1} равным единице, если P удовлетворяет строке s. Эмпирическая ошибка образца P относительно S и С есть число документов из S неклассифицированных по P (misclassified by P), то есть, errors,c(P) = SsÎS|P(s)-C(s)|.
Определение 2. Задача минимизации эмпирической ошибки.
Дана четверка объектов (S, S, C, k) – алфавит S, выборка S, целевое условие на S, константа k³0. Задача состоит в нахождении образца зависимых k-близких слов P, который минимизирует errors,c(P).
Как мы увидим в разделе 5, задача минимизации эмпирической ошибки имеет близкое отношение к задачи распознавания в зашумленных средах.
2.3 Суффиксные деревья
Суффиксные деревья – структура данных для хранения всех подслов данного текста в очень экономном виде (McCreight [24]). Пусть A = a1a2…an-1$ текст длины n. Мы примем, что текст всегда заканчивается специальным символом $ÏS отличным от символов алфавита. Для каждого 1£p£n обозначим суффикс, начинающийся в позиции p как Ap= ap…an-1$.
Тогда суффиксное дерево для текста A – в точности компактный луч (compact trie) для всех суффиксов(suffices) A, полученный из луча (trie) для A последовательным удалением внутренних вершин с только одним ребенком и слиянием меток удаленных ребер.
Более точно, суффиксное дерево для A – корневое дерево TreeA, которое удовлетворяет следующим условиям.
(i) Каждое ребро помечено подсловом a из А, которое кодируется парой (p,q) позиций вхождения a в строку A, то есть A[p]A[p+1]…A[q] = a.
(ii) Метки любых двух ребер исходящих из одной и той же вершины не могут начинаться с одной и той же буквы.
(iii) Каждая вершина v представляет собой строку Word(v) полученную конкатенацией меток на пути от корня до вершины v.
(iv) i-ый лист (1£i£n) li представляет собой суффикс ранга i в лексикографически отсортированном списке всех суффиксов A.
Пусть a - подслово A. Локус (местоположение) a в дереве TreeA, обозначаемый как Locus(a), есть уникальная вершина v дерева TreeA, такая что a - префикс строки Word(v) и Word(w) – подходящий префикс a, где w – предок вершины v.
Из свойств (iv) и (iii),
дерево TreeA имеет
в точности n листьев и
максимум n-1 внутренних
вершин. Таким образом, из свойства (i) требуется O(n) пространства памяти,
представляющее O(n2) подслов A. Кроме того, McCreight (1976) нашел
изящный алгоритм, который строит дерево TreeA за линейное время с линейным объемом памяти.
Известно, что средняя высота суффиксного дерева для строки длины n есть
O(log n) [7]. Это также верно для
случая генетических последовательностей.
2.4 Региональный поиск
Пусть n – положительное целое число. Имеется конечный набор точек X с целочисленными координатами на двумерной плоскости [1..n]x[1..n]. Процедура регионального поиска должна найти все точки из множества X, лежащие в заданном прямоугольнике [x1..x2]x[y1..y2].
Было предложено
несколько решений этой задачи, и среди них мы принимаем метод, описанный в
Preparata и Shamos [27] для простоты, хотя это - не оптимум по времени
вычисления. Их решение использует структуру данных, называемую региональное
дерево (orthogonal range tree), требующее O(m log m) памяти, O(m log m) операций
предобработки и O(log2m) операций поиска,
где m – число точек в X. Для алгоритма в
4-ом разделе, мы расширяем эту структуру для поиска в суффиксном дереве.
3 Алгоритм
В этом разделе мы покажем, существование эффективного алгоритма который вычисляет оптимизированный образец за время O(mn2 log(n)2), при затратах памяти O(kmn log n), используя такие структуры данных, как суффиксные деревья и деревья регионального поиска. Затем, в следующем разделе, мы покажем, что региональные запросы можно осуществлять прямо на суффиксном дереве, вместо регионального дерева. Это дает более быстрый алгоритм для задачи оптимизации доверия образца.
Ниже дан алгоритм Find_Optimal, который находит оптимизированные образцы. Ключевыми в алгоритме являются шаги перечисления образцов в канонической форме и быстрое вычисление supp(P) и conf(P). Пусть (S, S, C, k, s) является примером задачи оптимизации доверия образца.
Procedure Find_Optimal;
Вход: Выборка S = {s1,…,sm}, целевое условие C, близость k ³ 0 и Минимальная поддержка 0£s£1.
Выход: Оптимизированные образцы (a, k, b) в канонической форме.
Используемые структуры: приоритетная очередь Q.
begin
1
Q := Æ;
2
A := s1$s2…$sm$
и вычислить doc;
3 Построить суффиксное дерево TreeA и суффиксные массивы suf, pos.
4 Вычислить Diagk и Rankk из A.
5 for (каждой вершины v дерева TreeA) do вычислить I(v);
6 for (каждой вершины v дерева TreeA) do
7 for (каждой вершины u дерева TreeA) do
8
P := (Word(u),
k, Word(v));
9 Вычислить count(P,S1) и count(P,S0) путем выполнения
10 регионального запроса I(u) x I(v) для Rankk.
11 Вычислить supp(P) и conf(P);
12 If (supp(P) ³ s) then добавить P в приоритетную очередь Q с ключом conf(P);
13
end
for;
14
end
for;
15 Вывести все оптимизированные образцы из Q.
end proc.
3.1 Перечисление образцов в канонической форме с использованием суффиксного дерева
Пусть $ Ï S, такой что $ ¹ $. Возьмем в качестве входных данных S = {s1,…,sm} и С ® {0,1}. Наш алгоритм строит текст A := s1$s2…$sm$, называемый входным текстом, путем конкатенации всех документов из S, разделенных символом $. Пусть n = |A|. Для каждого 1£p£n определим doc(p) = i, если i-ый текст si включает p. Без потери общности, примем что существует некоторое 1£p£m, такое что С(si) = 1 для всех 1£i£p, С(si) = 0 для всех p<i£m.
Далее, мы строим суффиксное дерево TreeA для входного текста за линейное время [24]. Это дерево изоморфно обобщенному суффиксному дереву (generalized suffix tree, GST), являющегося компактным лучом (compacted trie) для всех суффиксов документов из S, кроме меток ребер направленных к листьям. Затем, для каждого листа мы переопределяем Word(v) как наибольший префикс суффикса, представленного вершиной v, не содержащий символов $. Это фактически стандартный метод построения GST за линейное время [3].
Введем отношение эквивалентности ºA следующим образом. Для строк a, b, a ºA b если OccA(a)=OccA(b) (совпадают местонахождения). Для образцов зависимых k-близких слов P=(a1, k, a2), Q=(b1, k, b2), P ºA Q, если a1 ºA b1 и a2 ºA b2. Если P ºA Q, тогда говорят, что P и Q эквивалентны.
Лемма 1. Эквивалентные образцы дают одинаковые значения для suppS(P) и confS(P).
Доказательство. По определению, эквивалентные шаблоны P, Q имеют то же самое множество местонахождений (occurrences) для любого текста A. Таким образом count(P,T) = count(Q,T) для любого подмножества T Í S. Из того, что suppS(P) и confS(P) определены через count, следует утверждение. ÿ
Образец считают находящимся в канонической форме, если он имеет форму (Word(u), k, Word(v)), для некоторых вершин u, v дерева TreeA. По определению, число образцов зависимых k-близких слов O(n2). Пусть ^S Î S - произвольная строка длины max{|s| | sÎS} + 1. Очевидно, что Ds, x(^S) = 0.
Лемма 2. Для любого образца зависимых k-близких слов P, если P удовлетворяет документу из S, тогда существует эквивалентный ему образец в канонической форме.
Доказательство. Пусть P=(a, k, b). Для любой подстроки A a,
существует вершина w дерева
TreeA, такая что a
ºA Word(w).
Предположим, что мы имеем неуплотненный суффиксный луч (uncompacted suffix trie) TreeA. Тогда существует вершина v
дерева TreeA, которая представляет a. Пусть w – самый высокий потомок v, который имеет, по меньшей мере, двух детей. Теперь, отобразим вершины TreeA в те TreeA, стандартным способом (we map the nodes in TreeA
into those in TreeA in a standard way). Теперь,
легко видеть, что v и w отобразились в те же самые
ребра в компактном варианте TreeA. Мы знаем, что
поддерево(v) и
поддерево(w) имеют
одинаковое множество листьев и, таким образом, мы имеем одинаковое множество
местонахождений (occurrences)
в A. Поскольку w = Locus(a)
в TreeA, мы имеем Word(w) ºA a.
Следовательно, получаем утверждение леммы. ÿ
Лемма 3. Для любого оптимального образца из образцов зависимых k-близких слов найдется эквивалентный образец P, который является либо каноническим либо ^S.
3.2 Вычисление значений поддержки с использованием региональных запросов
В этом разделе мы увидим, как быстро вычислить поддержку и доверие, используя региональные запросы. Техника, использованная здесь, в основном взята из Mander и Baeza-Yates [21]. Идея состоит в сведении поиска оптимального образца к рассмотрению прямоугольников со сторонами, параллельными осям, на двумерной плоскости рангов лексикографически упорядоченных суффиксов.
Пусть Ap1, Ap2, … , Apn – последовательность, полученная лексикографическим упорядочиванием всех суффиксов A. Здесь Ap – суффикс строки A, начинающийся в позиции p. Затем, сохраняем индексы p1,…,pn в массив suf: [1..n] ® [1..n] длины n в этом порядке, и определяем массив pos: [1..n] ® [1..n], как обратное отображение подстановки suf. Эти массивы называются суффиксными массивами (Gonnet, Baeza-Yates [14]; Manber, Myers [22]). По определению, suf(i) – позиция суффикса ранга i, pos(p) – ранг суффикса Ap.
Сначала, мы соблюдаем, чтобы для любой вершины v дерева TreeA, набор местонахождений слова Word(v) занимал смежный подинтервал I(v) = [x1..x2] в массиве suf.
Лемма 4. Подинтервалы I(v) для всех вершин v вычисляются за время O(n).
Доказательство. I(v) вычисляется проходом дерева TreeA, от листьев до корня, например
поиском в глубину. Просматривая листья слева направо, полагаем I(vi)
= [i..i] для i-го листа (i = 1,…,n). Затем, проходя дерево TreeA от листьев до корня, мы посещаем
каждую вершину v с её детьми v1, …, vh и полагаем I(v) = [L..R], где L – левая
граница интервала I(v1), R – правая граница интервала I(vh). ÿ
Далее, алгоритм строит из S
и C диагональное множество ширины k, которое представляет собой множество
помеченных точек на плоскости:
Diagk = { ( p, q;
doc(p) ) | 1 £ p,q £ n, 0 £ (q-p) £ k, doc(p) = doc(q)
}.
Затем алгоритм преобразует Diagk в следующее множество помеченных точек на
плоскости:
Rankk = {
(pos(p), pos(q); i) | (p, q; i) Î Diagk }
Для образца зависимых k-близких слов P = (a, k, b), мы рассмотрим двухмерный прямоугольный регион Rect(P)
= I(a) x I(b) и определим
count(Rect(P),Q) как число различных i таких что (x,y;i) Î Q Ç Rect(P) x [1..m], где Q – любое подмножество множества Rankk.
Лемма 5. Для
любого образца зависимых k-близких слов P, верно count(P,S) = count(Rect(P), Rankk).
Из леммы 5 задача вычисления suppS(P) и confS(P) свелась к задаче вычисления count(Rect(P), Rankk). В [27] стандартными способами показывают верность следующей леммы.
Лемма 6. Пусть i - любое число, Q Í [1..l]2 x [1..m] – множество помеченных точек на плоскости и R[1..n]2 – любой прямоугольник. Тогда, count(R,Q) вычисляется за время O(m log2n) с использованием памяти O(mn log n) с временем предобработки O(n log n), где n – число точек в Q.
Теорема 1. Пусть (S, S, C, k, s) является примером задачи оптимизации доверия образца. Тогда алгоритм Find_Optimal, данный выше, находит все оптимизированные образцы в канонической форме с близостью k и порогом поддержки s за время O(mn2 log2n) с использованием памяти O( kmn log(n) ), где m = card(S) и n = size(S).
Доказательство. Сначала мы
строим суффиксное дерево за линейное время с линейными расходами памяти. Затем,
вычисляем интервалы I(v) для всех вершин v за время O(n) с использованием алгоритма динамического программирования (Preparata и Shamos 1985). Из леммы 1 и леммы 3, это
достаточно для поиска самое большее O(n2)
канонических образцов P
= (Word(u), k, Word(v)),
перечислением пар u, v вершин дерева TreeA. Затем, мы можем видеть из
леммы 5 и леммы 6, что для каждого P мы вычисляем supp(P) и conf(P) за время O(knm
log n) предобработки, используя O(kmn log
n) памяти, время единичного запроса O(m log2n). Обратите
внимание, что число Rankk самое большее kn. Поскольку
число возможных шаблонов в канонической форме O(n2), утверждение доказано. ÿ
4 Модифицированный алгоритм
В этом разделе мы представляем модифицированную версию нашего алгоритма, которая выполняется за время O(max{k,m}n2) с использованием памяти O(kn). В этом алгоритме реализуется механизм регионального поиска непосредственно на суффиксном дереве, вместо запроса на региональном дереве, и вычисляем значения count(Rect(P),Rankk) методом динамического программирования, подобным изложенному в Maass [20].
Procedure Modified_Find_Optimal;
Вход: Выборка S = {s1,…,sm}, целевое условие C, близость k ³ 0 и Минимальная поддержка 0£s£1.
Выход: Оптимизированные образцы (a,k, b) в канонической форме.
Используемые структуры: приоритетная очередь Q.
begin
1
Q := Æ; A := s1$s2…sm, вычислить doc;
2 Построить суффиксное дерево TreeA и суффиксные массивы suf, pos;
3 Вычислить Diagk и Rankk.
4 for (каждой вершины u дерева TreeA, обходимых с листьев до корня) do
5
if (u – x-ый лист lx) then
6
B(lx)
:= { <y,z> | <x,y,z> Î Rankk, $y, $z};
7 If (u – интервальная вершина с детьми u1, …, uh) then
8
B(u)
:= B(u1) È … È B(uh),
затем выбрасываем (discard) B(u1), …, B(uh);
9 for (каждой вершины v дерева TreeA, обходимого с листьев до корня) do
10
if (v – y-ый лист ly) then
11
С(ly)
:= {<z> | <y,z>Î B(u), $z };
12 if (v – интервальная вершина с детьми v1, …, vh) then
13 C(v) := C(v1) È … È B(vh), затем выбрасываем (discard) B(v1), …, B(vh);
14
P := (Word(u),
k, Word(v) );
15
Вычислить count(P,S1) и count(P, S0) из C(v);
16
if (supp(P) ³
s) then
17 Добавить P в Q с ключом conf(P);
18
end
for;
19
end
for;
20 Вывести все образцы из Q.
end proc.
Каждая вершина v дерева TreeA имеет линейные списки B(v) и C(v). Элементами B(v) являются пары <y,z> Î [1..n] x [1..m] и сортируются по координате y. Аналогично, элементы C(v) метки <z> Î [1..m] сортируются по координате z. Для любого x Î [1..n], обозначим как lx x-ый лист.
Лемма 7. Предположим, алгоритм Modified_Find_Optimal посещает вершину u в цикле (строка 4), посещает вершину v в цикле (строка 9) и достигает строки 15. Тогда C(v) – упорядоченный список z, такой что (x,y;z) Î Rankk Ç Rect(P) x [1..m].
Доказательство. Доказывается индукцией по высоте вершин u и v подобным образом как в 4-ой лемме. ÿ
Теорема 2. Пусть (S, S, C, k, s) является примером задачи оптимизации доверия образца. Тогда алгоритм Modified_Find_Optimal находит все оптимальные образцы в канонической форме близости k и порогом поддержки s за время O(max{k,m}n2) с используемым объемом памяти O(kn), где m = card(S), n = size(S).
Доказательство.
Утверждение следует из леммы 1, леммы 3, леммы 5 и леммы 7. Оцениваем время.
Строка 1 – строка 3 расходует время O(n + kn). Поскольку дерево TreeA содержит O(n) вершин, внешний цикл (строка 4)
выполняется за время O(n) и, таким образом,
внутренний цикл (строка 9) выполняется за время O(n2). В каждом посещении вершины u во внешнем цикле каждая операция
объединения (строка 8) занимает время O(kn)
потому что длина получаемого списка B(u) очевидно ограничена числом kn = card(Rankk). Строка 6 алгоритма дает общее время O(kn) просмотра всех листьев. Аналогично,
каждое посещение вершины v
во внутреннем цикле, каждая операция объединения (строка 13) дает время O(hm) потому что каждый C(vi) отсортирован и его длина ограничена числом m, где р – число детей.
Поскольку суммарное количество детей всех вершин O(n), амортизированное общее время строки 13 O(mn). Амортизированное время строки 11 O(kn) – просмотр всех листьев фиксированной вершины u. Объединяя эти наблюдения
получаем, что полное время выполнения алгоритма T(n) = O(kn) + O(kn) + n *
(O(kn) + O(mn) )= O(max{k,m}n2). ÿ
Известно, что высота суффиксного дерева O(log n) для случайных текстов
сгенерированных равномерным распределением [7]. На основании теоремы 3 мы с высокой
вероятностью ожидаем эффективного выполнения алгоритма за время O(kn log3n) для таких случайных текстов.
Теорема 3. Пусть (S, S, C, k, s) является примером задачи оптимизации доверия образца. Тогда существует алгоритм который вычисляет все оптимальные образцы в канонической форме близости k и порогом поддержки s за время O(kd2n log n ) используя O(kn) памяти, где n = size(S), d – высота суффиксного дерева.
Доказательство. Заметим, что каждый слой, набор вершин
на одном уровне, суффиксного дерева содержит Т = kn элементов в B(u) (C(u)). В
модифицированном алгоритме мы связываем с каждой вершиной указатель на её
родителя и отсортированный список C(v) и B(u) точек <y,z> и <x,y,z>. Мы используем сбалансированные деревья
для представления каждого списка C(v), так чтобы мы могли осуществить вставку элементов и
подсчет положительно помеченных или отрицательно помеченных элементов за время log
l для l = card(C(v)). Используя их, мы проходим уровни дерева (tree levelwise) от листьев до корня. Таким образом, в каждой вершине u со списком
B(u), мы можем вычислить все C(v) за время O(dn0 log n0) (строка 10 – строка 17
алгоритма), где n0 = card(B(u)). Неоднократно повторяя это рассуждение, мы можем получить
оценку O(kd2n log n). Мы
опускаем детали. ÿ
5 Agnostic PAC-learning и минимизация эмпирической ошибки
Agnostic PAC-learning – обобщение хорошо знакомой в вычислительной
теории обучения (computational learning theory) модели PAC – learning, которая предназначается для захвата изучаемых ситуаций из реального мира
(intended to capture learning situation in real world) [16, 17, 20]. В модели Agnostic PAC-learning самообучающийся алгоритм может корректно работать с зашумленными
средами, и даже имеют возможность аппроксимировать произвольное неизвестное
распределение вероятности.
Haussler [16] и Kearns [17] показали близкую связь между Agnostic PAC-learning и задачей минимизации эмпирической ошибки, определенную выше. Величина Vapnik-Chervonenkis (VC-величина, VC-dimension) измеряет сложность класса понятий (concept class) (см. например [16,17]). Класс образцов зависимых k-близких слов, очевидно, имеет полиномиальную VC-величину для любого фиксированного неотрицательного k.
Лемма 8 (Kearns и др. [17]). Для любого гипотетического класса с
полиномиальной VC-величиной,
полиномиальная разрешимость задачи минимизации эмпирической ошибки эквивалентна
существованию эффективной модели Agnostic PAC-learning (… and the efficient agnostic PAC-learnability are equivalent).
Теперь мы
покажем, как можно модифицировать алгоритм Modified_Find_Optimal для решения
задачи минимизации эмпирической ошибки с теми же самыми оценками для времени и
памяти.
Теорема 4. Пусть S – выборка, C – целевое условие на S, k³0 – фиксированная константа. Тогда
существует алгоритм, который решает задачу минимизации эмпирической ошибки для
образцов зависимых k-близких
слов за время O(kd2n log n) используя O(kn)
памяти, где n = size(S),
d – высота суффиксного дерева.
Доказательство. Можно легко показать, что минимизация
эмпирической ошибки очевидно эквивалентна максимизации разности DS,C
= count(P,S1) – count(P,S0). Несложно видеть, что DS,C максимизируется любым шаблоном в
канонической форме или ^S по лемме 3. Теперь мы модифицируем алгоритм
Modified_Find_Optimal для нахождения шаблона, который максимизирует DS,C.
В строке 15 алгоритма мы считаем count(P,S1) и count(P,S1) и затем DS,C. Мы пропускаем проверку условия в строке 16
и затем в строку 17 добавляем P
в приоритетную очередь Q
с DS,C в качестве ключа. Модификация корректно
работает, следовательно, утверждение нашей теоремы следует из теоремы 3. ÿ
Хотя задача
минимизации эмпирической ошибки трудна для большинства классов понятий (concept class), недавно некоторые геометрические образцы,
такие как прямоугольники со сторонами, параллельными осям координат и выпуклые n-угольники на евклидовой плоскости, показали
эффективную agnostic PAC-обучаемость (learnable) [8, 20]. Из леммы 8 и теоремы 4 мы знаем,
что существует (agnostic learning) алгоритм,
который выполняется за время O(kn log3n), если входная выборка гарантировано
случайная. Следовательно, наш результат - один из
нескольких результатов на эффективную агностическую обучаемость для
нетривиального класса понятий, но другой чем геометрические образцы.
6 Обрезание и выборка
Обрезание (pruning): Основано на
монотонности поддержки образцов в канонической форме (W(u),
k, W(v)),
-
если u – предок v тогда supps(u) ³ supps(v),
-
если min{supps(W(u)), supps(W(v))} < s, тогда supps (<W(u),k,W(v)>)
£ s.
Мы объединяем две эвристики обрезания в первом алгоритме: (1) Локальное
обрезание. Обрезаем потомков вершины u
если supps(W(u)) £
s для некоторой u. (2) Глобальное обрезание. Обрезаем
потомков вершины v если
supps(<W(u),k,W(v)>)
£ s, где supp(a) – поддержка подслова
a. Локальное обрезание также возможно во втором алгоритме. Подобно как в доказательстве теоремы 2, мы
знаем, что самое большее kd2n
канонических образцов с ненулевой поддержкой для высоты d суффиксного дерева. Таким образом, мы можем
ожидать, что эффективность первого алгоритма улучшится с обрезанием, для почти
случайных текстов.
Выборка (sampling): Модифицированный
алгоритм в 4-ом разделе достигает времени выполнения O(mn2) но это
недостаточно быстро для применения к огромным текстовым базам данных в
несколько гигабайт. Следующая процедура приближает решение применением
технологии случайной выборки.
Вход: Выборка S, состоящая из n примеров.
begin
Выбрать m документов из S используя равномерное распределение.
Пусть Sm – полученная выборка.
Используя алгоритм Find_Optimal, найти оптимальные образцы P относящиеся к Sm и выдать их в качестве результата.
end.
Мы устанавливаем размер выборки, скажем O(n1/3) так, чтобы
алгоритм работал почти за линейное время от n. Образцы, полученные для случайной выборки,
могут давать доверие ниже, чем образцы, полученные для исходной выборки S. Поэтому мы представляем эмпирические
оценки для эвристики выборки.
7 Экспериментальные результаты.
Мы проводили
эксперименты на генетических данных для
определения эффективности наших алгоритмов. Программа была написана на C, основывалась на втором алгоритме (из 4-го
раздела) и запускалась на оборудовании Sun Ultra 1 под управлением операционной системы Sun Solaris 2.5. Последовательности нуклеотидов общим
объемом 24KB взяты из базы данных GenBank [11]. Мы получили 450 положительных
последовательностей относящихся к сигнальным пептидам, и 450 отрицательных
последовательностей 450 из других последовательностей, и предобработатывали данные, преобразовывая
двадцать аминокислот в три символа 0,1,2 индексами из Kyte и Doolittle
(1982). Для каждого m = 10 ~ 100 и каждого испытания мы случайно выбирали m
положительных и m отрицательных последовательностей из исходной выборки S и
вычисляли оптимальные образцы для полученной выборки.
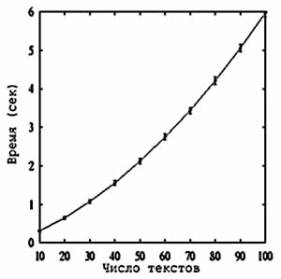
Время
работы. На
рисунке можно увидеть зависимость времени работы алгоритма от числа документов m, которое
пропорционально размеру выборки n. Мы видим, что рост времени является более медленным, чем
мы это ожидали из теоремы 2. Для большей выборки, размером 24KB (m = 450),
алгоритм работает одну минуту и требует более 20MB памяти, при этом находит 37
оптимальных образцов, проверяя 676 часто повторяющихся из 577296729 возможных
образцов. Примерами оптимальных образцов являются “12222”*”2” и “0”*”2222”,
достигающие доверия 69% и 66% при поддержке 65%.
Случайная
выборка.
Рисунок показывает результат применения эвристики выборки (sampling).
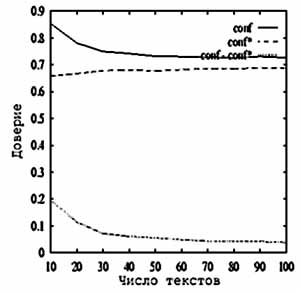
Для каждого испытания сначала вычисляются лучшие десять образцов выборки
Sm, затем
оценивается эмпирическое значение
доверия conf
для Sm и
действительное значение доверия conf* для S. Мы отобразили среднее значение доверия для
100 испытаний для каждого m.
Параметры были k = 5,
s = 0.6. На рисунке можно видеть, что ошибка доверия – 5% для 10% выборки. Для значения поддержки мы имели
подобный результат (12% ошибок).
Обрезание (pruning): На таблице
показана эффективность применения эвристики обрезания.
|
s |
Размер выборки (байт) |
Всего вариантов |
Локально частых |
Глобально частых |
|
90% |
2701 |
7,295,401 |
121 |
40 |
|
50% |
2754 |
7,584,516 |
1,444 |
64 |
|
30% |
2764 |
7,639,696 |
6,241 |
88 |
Выборка состояла из 50 положительных и 50 отрицательных последовательностей, общим размером 2.7KB. Первый и второй столбцы показывают минимальную поддержку и размер выборки; третий, четвертый и пятый – число образцов изначально, оставшихся после локального обрезания и после глобального. Мы можем видеть, что только небольшая часть образцов может быть разрешима для почти случайной последовательности.
8 Заключение
В этой статье мы рассмотрели задачу поиска правил зависимости для подстрок и дали эффективный алгоритм, который находит оптимальные правила (optimized confidence rules) из большого набора неструктурированных текстовых данных для класса образцов зависимых двух слов. Мы обсудили работу алгоритмов, эвристики и проведение экспериментов с генетическими данными.
Алгоритмы, данные в этой статье, эффективно используют структуру данных суффиксные
массивы, которая представляет собой вариант суффиксного дерева, являющимся более эффективным и подходящим для осуществления функций
продвинутого поиска в больших текстовых базах данных (Gonnet и Baeza-Yates [14]; Manber и Myers [22]).
Таким образом, это - будущая задача разработки масштабируемых методов
реализации суффиксных массивов, которая позволяет включить наши алгоритмы в
существующие текстовые базы данных. Изучение применения алгоритма для вторичных
устройств хранения и ускорение для параллельного выполнения – другие будущие
задачи.
Мы разработали эффективный обучающийся алгоритм для класса
структурированных шаблонов [4-6]. Было бы интересно расширить структуру
образцов, введенных в этой статье.
Ссылки
1. S. Abiteboul,
Querying semistructured data. In Proc. ICDT'97 (1997).
2. R. Agrawal, T.
Imielinski, A. Swami, Mining association rules between sets of items
in large databases.
In Proc. the 1993 ACM SIGMOD Conference on Management
of Data, 207--216
(1993).
3. A. Amir, M.
Farach, Z. Galil, R. Giancarlo, K. Park, Dynamic Dictionary Match
ing. JCSS, 49
(1994), 208-222.
4. H. Arimura, R.
Fujino, T. Shinohara, and S. Arikawa. Protein motif discovery
from positive
examples by minimal multiple generalization over regular patterns
Proc. Genome
Informatics Workshop 1994, 39-48, 1994.
5. H. Arimura, H.
Ishizaka, T. Shinohara, Learning unions of tree patterns using
queries, Theoretical
Computer Science, 185 (1997) 47-62.
6. H. Arimura, T.
Shinohara, S. Otsuki. Finding minimal generalizations for unions
of pattern languages
and its application to inductive inference from positive data.
In Proc. the 11th
STACS, LNCS 775, (1994) 649-660.
7. L. Devroye, W.
Szpankowski, B. Rais, A note on the height of the suffix trees.
SIAM J. Comput., 21,
48-53 (1992).
8. D. P. Dobkin and
D. Gunopulos, Concept learning with geometric hypothesis. In
Proc. COLT95 (1995)
329-336.
9. R. Feldman and I.
Dagan, Knowledge Discovery in Textual Databases (KDT). In
Proc. KDD95 (1995).
10. T. Fukuda, Y.
Morimoto, S. Morishita, and T. Tokuyama, Data mining using
twodimensional
optimized association rules. In Proc. the 1996 ACM SIGMOD
Conference on
Management of Data, (1996) 13-23.
11. GenBank, GenBank
Release Notes, IntelliGenetics Inc. (1991).
12. G. Gras and J.
Nicolas, FOREST, a browser for huge DNA sequences. In Proc. the
7th Workshop on
Genome Informatics (1996).
13. G. Gonnet, PAT
3.1: An efficient text searching system, User's manual. UW Center
for the New OED,
University of Waterloo (1987).
14. G. Gonnet, R.
BaezaYates, Handbook of Algorithms and Data Structures,
AddisonWesley
(1991).
15. J. Han, Y. Cai,
N. Cercone, Knowledge discovery in databases: An attribute
oriented approach.
In Proc. the 18th VLDB Conference, 547-559 (1992).
16. D. Haussler,
Decision theoretic generalization of the PAC model for neural net and
other learning
applications. Information and Computation 100 (1992) 78-150.
17. M. J. Kearns, R.
E. Shapire, L. M. Sellie, Toward efficient agnostic learning.
Machine Learning,
17(2--3), 115-141, 1994.
18. J. Kyte and R.
F. Doolittle, In J. Mo. Biol., 157 (1982), 105-132.
19. D. D. Lewis,
Challenges in machine learning for text classification. In Proc. 9th
Computational
Learning Theory (1996), pp. 1.
20. W. Maass,
Efficient agnostic PAClearning with simple hypothesis, In
Proc. COLT94 (1994),
67-75.
21. U. Manber and R.
BaezaYates, An algorithm for string matching with a sequence
of don't cares. IPL
37, 133-136 (1991).
22. U. Manber and E.
Myers, ``Suffix arrays'': a new method for online string searches.
In Proc. the 1st ACMSIAM
Symposium on Discrete Algorithms (1990)319-327.
23. H. Mannila, H.
Toivonen, Discovering generalized episodes using minimal occur
rences. In Proc.
KDD'96 (1996) 146-151.
24. E. M. McCreight,
A spaceechonomical suffix tree constructiooon algorithm. JACM
23 (1976), 262-272.
25. M. Nakanishi, M.
Hashidume, M. Ito, A. Hashimoto, A lineartime algorithm for
computing characteristic
strings. In Proc. the 5th International Symposium on
Algorithms and
Computation (1994), 31523.
26. OPENTEXT Index.
http://index.opentext.net
(1997).
27. F. P. Preparata,
M. I. Shamos, Computational Geometry. SpringerVerlag (1985).
28. J. T.L. Wang,
G.W. Chirn, T. G. Marr, B. Shapiro, D. Shasha, K. Zhang. Com
binatorial Pattern
Discovery for Scientific Data: Some preliminary results. In
Proc. 1994 SIGMOD
(1994) 115-125.